Troubleshooting
Problem
Call home SRC E3325009 occurs when the primary HMC fails to remaster within the time window for arbitration. This event is reported to notify the customer that the managed system might be running without a primary HMC to perform problem analysis if a service event were to occur against the system. The primary HMC function is critical to ensure hardware events are reported and called home to IBM.
Symptom
Call home SRC E3325009 is listed on the HMC, under Manage Serviceable Events or in lssvcevents -t hardware, reported against the HMC MTMS that is the primary HMC. The SRC E3325009 is reported at least once per day due to the scheduled operation that runs for rearbitration. It can also be reported due to an HMC reboot or if the managed system is removed and readded to the HMC.
Cause
The HMC has 15 minutes to remaster and establish a primary analyzing HMC when arbitration runs. If it doesn't, the HMC will report the SRC and call home to IBM. This is to report that the customer has a managed system without a primary HMC to perform problem analysis and call home system level errors, SRC events. This SRC reported at Version 9 is due to:
1. The rearbitration schedule in V9, which causes the SRC to be reported once a day.
2. Communication attempts between the primary HMC and the secondary HMC across all interfaces, which leads to exceeding the timeout value.
3. Connectivity issues between the HMC and one or more managed systems where the lssysconn -r all command shows the state as "No Connection", "Pending Authentication", "Failed Authentication"
Environment
Version 9.1 M930 + any additional PTFs
Any HMC Hardware Appliance platform or Virtual Appliance platform
Diagnosing The Problem
Call home SRC E3325009 is generated every day around the same time
Resolving The Problem
If the issue has to do with Connectivity to one or more managed systems, resolve the connectivity state of "No Connection", "Pending Authentication", or "Failed Authentication" as seen in the lssysconn -r all output. After resolving the connectivity issues monitor for no more reoccurrences of the SRC reporting.
If the issue is not related to connectivity, the full fix which includes the M940 fixes for E3325009 plus an ipv6 disablement update is now available in the V9.1 M941 Service Pack Release
PTF MH01859 HMC V9 R1.941.0 Service Pack - for 7042 Machine Types or vHMC for x86 hypervisors (5765-HMW)
PTF MH01860 HMC V9 R1.941.0 Service Pack - for 7063 Machine Types or vHMC for PowerVM (5765-HMB)
Another fix is available specific to any configuration that includes Virtual HMC arbitration in HMC V9 R1.941.2:
PTF MH01864 HMC V9 R1.941.2 - for 7042 Machine Types or vHMC for x86 hypervisors (5765-HMW)
PTF MH01865 HMC V9 R1.941.2 - for 7063 Machine Types or vHMC for PowerVM (5765-HMB)
Fixed vHMC MTMS parsing logic for primary HMC arbitration to handle virtual HMCs uniquely to prevent the chprimhmc command error "Failed to get service operation information from peer" and subsequent E3325009 reporting.
Step 1. In *ALL* environments where ipv6 is not used, ensure ipv6 is disabled: chhmc -s disable --ipv6 -c network
NOTE: Step 2 is a very important sequence in resolving the reporting of E3325009. Step 2 clears the cached network and interface entries between the HMCs and allows the HMCs to perform fresh connection discovery of each other. This resolves why the HMCs were unable to connect and prevents E3325009 from reporting.
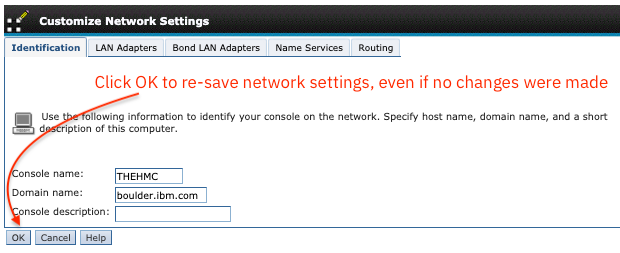
Step 2. *DO NOT SKIP THIS STEP* Re-save the settings for the network on each HMC. Navigate to Console Settings -> Change Network Settings -> click LAN Adapters and verify:
- Each ethX is set with the expected IP address correctly
- References to localhost or localdomain are not listed under Name Services tab or under the Identification tab.
Then click OK to re-save the settings, even if no changes were made. Reboot each HMC one at a time to refresh the information for primary arbitration, starting with the HMC not reporting the E3325009 event, followed by the HMC reporting the E3325009 event.
If E3325009 continues to report the most likely cause is the HMC has a reference to an HMC name or IP address that is no longer valid or reachable.
Some examples include:
- The order the HMCs were rebooted caused one HMC to not get refreshed with the new network information. Reboot the HMC reporting the E3325009 one more time.
- An older HMC model was replaced with a new model and given the same hostname and IP address
- An HMC name or IP address was updated in DNS, but the changes have not been made on the HMC itself
- Port 9920 is blocked in the HMC firewall or in the customer's firewall between the HMCs
FURTHER TROUBLESHOOTING STEPS IF Step 1 and 2 do not mitigate the reporting of E3325009:
1. Verify that all the ipaddresses defined on the HMC are correct and in use:
hmc01>lshmc -n -Fhostname:ipaddr
hmc01:10.1.1.10,11.9.9.9,10.0.0.32
2. If an ipaddress was decommissioned or is not supposed to be in use by the HMC, remove it from the configuration in the "Change Network Settings" menu under HMC Management. Continue with the additional steps for further network validation before rebooting both HMCs.
Example: hostname is hmc01 and ipaddress is 10.1.1.10
hostname is hmc02 and ipaddress is 10.1.1.20
2a. If DNS is not in use, ensure a unique hostname is set, not localhost, and skip to step 3.
2b. If DNS is in use, verify the dns setup is identical on both HMCs.
From hmc01:
hmc01>lshmc -n -Fhostname:domain:nameserver:dns:domainsuffix
hmc01:boulder.ibm.com:10.0.130.50,10.0.128.50:enabled:boulder.ibm.com
From hmc02:
hmc02>lshmc -n -Fhostname:domain:nameserver:dns:domainsuffix
hmc02:boulder.ibm.com:10.0.130.50,10.0.128.50:enabled:boulder.ibm.com
2c. Check forward and reverse lookup matches on both HMCs for each other.
From hmc01:
hmc01>host hmc02
hmc02.boulder.ibm.com had address 10.1.1.20
hmc01>host 10.1.1.20
10.1.1.20 in-addr.arpa domain name pointer hmc02.boulder.ibm.com
From hmc02:
hmc02>host hmc01
hmc01.boulder.ibm.com had address 10.1.1.10
hmc02>host 10.1.1.10
10.1.1.10 in-addr.arpa domain name pointer hmca01.boulder.ibm.com
The reverse lookup shows hmca01 not hmc01, which is not a match. The DNS records need to be fixed to ensure forward and reverse lookup match.
3. Verify that port 9920 is open in the firewall for all interfaces on both HMCs with no restriction on the allowed host:
hmc01>lshmc --firewall | grep 9920
interface=eth1,application=FCS,"ports=9920:tcp,udp:9900",allowedhost=0.0.0.0/0.0.0.0
interface=eth2,application=FCS,"ports=9920:tcp,udp:9900",allowedhost=0.0.0.0/0.0.0.0
interface=eth0,application=FCS,"ports=9920:tcp,udp:9900",allowedhost=0.0.0.0/0.0.0.0
interface=eth1,application=FCS,"ports=9920:tcp6,udp6:9900",allowedhost=::/::
interface=eth2,application=FCS,"ports=9920:tcp6,udp6:9900",allowedhost=::/::
interface=eth0,application=FCS,"ports=9920:tcp6,udp6:9900",allowedhost=::/::
Repeat the lshmc --firewall command from hmc02 and verify the same results.
4. Verify 9920 is connected between the HMCs and shows as "ESTABLISHED":
hmc01>cat $(ls -tr /dump/HMCMonitor/netstat* | tail -1) | grep 9920 | grep 10.1.1.20
tcp6 0 0 10.1.1.10:9920 10.1.1.20:37976 ESTABLISHED 7340/java
hmc02>cat $(ls -tr /dump/HMCMonitor/netstat* | tail -1) | grep 9920 | grep 10.1.1.10
tcp6 0 0 10.1.1.20:39998 10.1.1.10:9920 ESTABLISHED 7952/java
5. Verify with the network administrator that no firewall is blocking port 9920 between the HMCs for communication if the 9920 port shows any other status than ESTABLISHED or is not present.
6. Verify each HMC knows who is primary for each managed system after a reboot:
From hmc01:
hmc01>lsprimhmc -m 9009-42A-78XXXXX
is_primary=1,primary_hmc_mtms=VM-Vdxx-xxx/xxxxxxx,primary_hmc_ipaddr=10.1.1.10,primary_hmc_hostname=hmc01
From hmc02:
hmc02>lsprimhmc -m 9009-42A-78XXXXX
is_primary=0,primary_hmc_mtms=VM-Vdxx-xxx/xxxxxxx,primary_hmc_ipaddr=10.1.1.10,primary_hmc_hostname=hmc01
If the output shows good values and good communication, E3325009 may report one time around the HMC rebooted for one or more managed systems due to timing, but will stop reporting on the daily schedule basis. If the output shows blank values from either HMC, then the HMCs are still not communicating with each other and E3325009 will continue reporting every day. A pedbg -c -q 4 collection from both HMCs is necessary for further debugging of the problem. Contact IBM hardware support for additional assistance.
Blank value example:
hmc02>lsprimhmc -m 9009-42A-78XXXXX
is_primary=0,primary_hmc_mtms=,primary_hmc_ipaddr=,primary_hmc_hostname=
Internal Use Only

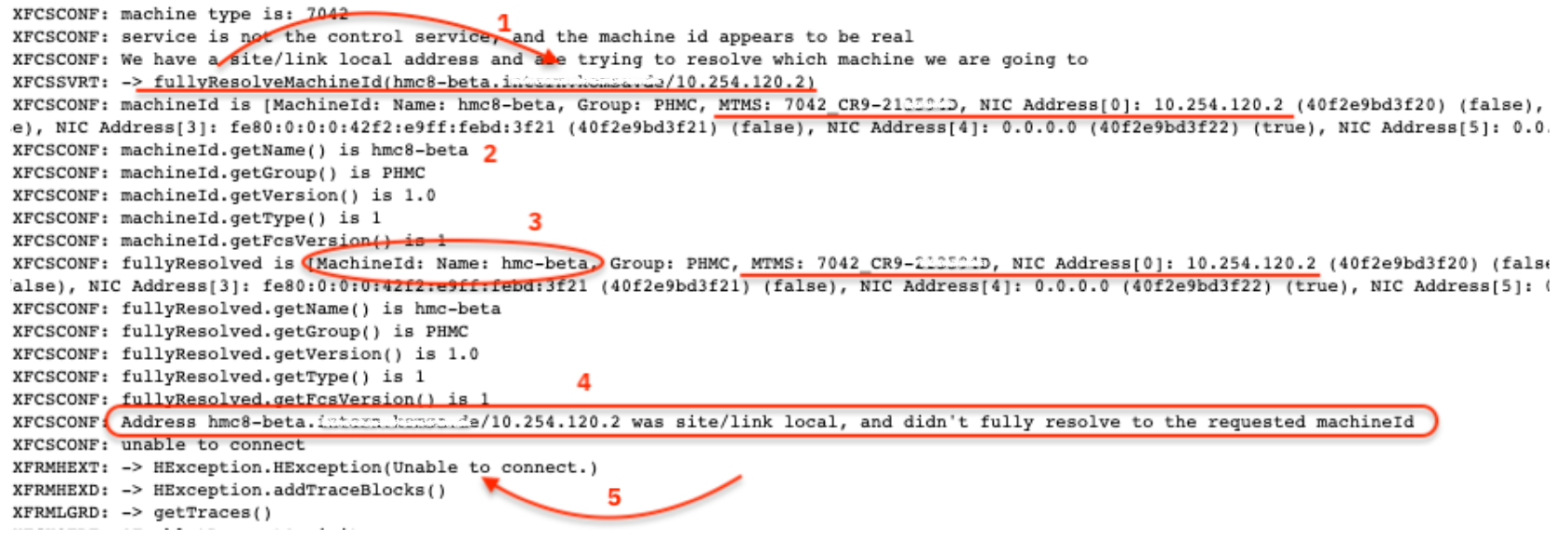
Scroll to the bottom of the E332 entry and look for the fullyResolveMachineId section; which will include a parsing of what FCS has for the HMC ethX entries. When E3321037 is logged, there will be a mis-match in the machineId entry versus the fullyResolved entry. This is why Step 2 performed on both HMCs in the action plan is the MOST IMPORTANT step, especially once all name resolution is resolved OR when no network issue is identified, yet E3325009 continues to report. This mismatch is cached network settings, which get refreshed on the "click OK" during the save network settings and subsequent reboot.
2020-06-04@10:21:04.542809 00004493:000083E8 XFCSCONF: machineId is [MachineId: Name: hmc21857, Group: PHMC, MTMS: 7063_CR1-130XXXX, NIC Address[0]: 10.177.181.91 (ac1f6b0fa944) (false), NIC Address[1]: fe80:0:0:0:ae1f:6bff:fe0f:a944 (ac1f6b0fa944) (false), NIC Address[2]: 10.0.255.1 (ac1f6b0fa945) (true), NIC Address[3]: fe80:0:0:0:ae1f:6bff:fe0f:a945 (ac1f6b0fa945) (true), NIC Address[4]: 0.0.0.0 (ac1f6b0fa946) (true), NIC Address[5]: 0.0.0.0 (ac1f6b0fa947) (true)]
2020-06-04@10:21:04.542822 00004493:000083E8 XFCSCONF: machineId.getName() is hmc21857
2020-06-04@10:21:04.542836 00004493:000083E8 XFCSCONF: machineId.getGroup() is PHMC
2020-06-04@10:21:04.543067 00004493:000083E8 XFCSCONF: machineId.getVersion() is 1.0
2020-06-04@10:21:04.543074 00004493:000083E8 XFCSCONF: machineId.getType() is 1
2020-06-04@10:21:04.543081 00004493:000083E8 XFCSCONF: machineId.getFcsVersion() is 1
2020-06-04@10:21:04.543110 00004493:000083E8 XFCSCONF: fullyResolved is [MachineId: Name: hmc21857, Group: PHMC, MTMS: 7063_CR1-130XXXX, NIC Address[0]: 10.177.181.91 (ac1f6b0fa944) (false), NIC Address[1]: 10.0.255.1 (ac1f6b0fa945) (true), NIC Address[2]: 0.0.0.0 (ac1f6b0fa946) (true), NIC Address[3]: 0.0.0.0 (ac1f6b0fa947) (true)] NIC 4 and NIC 5 don't exist here
2020-06-04@10:21:04.543121 00004493:000083E8 XFCSCONF: fullyResolved.getName() is hmc21857
2020-06-04@10:21:04.543127 00004493:000083E8 XFCSCONF: fullyResolved.getGroup() is PHMC
2020-06-04@10:21:04.543132 00004493:000083E8 XFCSCONF: fullyResolved.getVersion() is 1.0
2020-06-04@10:21:04.543142 00004493:000083E8 XFCSCONF: fullyResolved.getType() is 1
2020-06-04@10:21:04.543148 00004493:000083E8 XFCSCONF: fullyResolved.getFcsVersion() is 1
2020-06-04@10:21:04.543159 00004493:000083E8 XFCSCONF: Address /10.177.181.91 was site/link local, and didn't fully resolve to the requested machineId
The code is attempting to (1) fully resolve the hostname and ipaddress of the HMC MachineId. In the below example, (3) hmc-beta is the actual hostname for ipaddress 10.254.120.2. When the HMC was original setup the hostname was set to (2) hmc8-beta. This is not a match, since the (4) MachineID did not full resolve to exactly the same thing, (5) unable to connect is returned.
Was this topic helpful?
Document Information
Modified date:
30 October 2023
UID
ibm11073300